Introduction
After launching the video generation app Sora, OpenAI is making a strong push into the image generation field with a newly upgraded AI model.
At 3 AM Beijing time, OpenAI CEO Sam Altman led a 20-minute live stream to officially release ChatGPT Images 2.0, the company’s most powerful image generation model to date.
Key Features of ChatGPT Images 2.0
Unlike earlier models, ChatGPT Images 2.0 is a model with cognitive abilities. It can search the internet for the generation topic, self-verify, and even produce up to 8 coherent images at once.
During the live stream, Altman praised the new model, stating, “Images 2.0 is a huge leap, like jumping from GPT-3 to GPT-5. Its ability to create stunningly beautiful works is astonishing.” This metaphor quickly sparked discussions in the tech community.
Improvements Over Previous Versions
The model shows significant improvements in:
- Following detailed instructions
- Accurately positioning and relating objects
- Rendering dense text
It supports image generation in any aspect ratio, can stably render small text, icons, UI, and complex compositions, and supports up to 2K resolution, making the output more aligned with user needs and suitable for direct commercial use.
More importantly, its grasp of composition and visual aesthetics reduces the “AI feel” of generated results, giving them a more deliberately designed quality. It also adapts well to multiple languages, using its expanded visual and world knowledge to supplement information, allowing users to achieve smarter images with fewer prompts.
Generation Modes
ChatGPT Images 2.0 offers two generation modes: Fast Mode and Thinking Mode. OpenAI technicians mentioned that Thinking Mode is particularly useful for generating images that require a lot of specific data and information. This mode allows the model to perform “secondary verification” and search for information online, even generating scannable QR codes.

One of the model’s most significant new features is the ability to generate multiple images at once. Previous AI models would only split a single image into multiple grids when asked to generate multiple versions; the new model can output multiple independent image files while maintaining consistency in content, ensuring that characters and scenes remain uniform across all images.
Leveraging OpenAI’s reasoning model’s intelligence and deep understanding of the visual world, this model elevates image generation from mere rendering to a strategic design level, transforming it from a tool into a visual system that helps people turn ideas into understandable, shareable, teachable, and expandable visual outcomes. Starting now, all ChatGPT, Codex, and API users can access this feature.
Additionally, the new model supports various aspect ratios and resolutions, including 360° panoramic images. Altman also noted that Images 2.0 has significantly improved capabilities in accurately rendering multilingual text.
Core Features Summary
In summary, the core features of ChatGPT Images 2.0 include:
- Precise instruction following and relationship understanding: Can accurately execute complex long instructions, correctly place object relationships, and clearly render dense text.
- Cognitive abilities: Can search for real-time information online and self-verify before generation, making it the first image model with reasoning and planning capabilities.
- Coherent multi-image generation: Can output up to 8 stylistically coherent images in a single command.
- 2K ultra-clear and flexible composition: Supports output up to 2K resolution, with aspect ratios flexibly extending from 3:1 to 1:3.
- Significant leap in multilingual text rendering: Correctly spells non-Latin characters like Chinese, Japanese, and Korean, integrating them naturally into designs.
Altman mentioned during the live stream that this model could be used to generate complete magazine layouts and even entire comics, indicating that commercial use of this model is feasible.
In an interview on the podcast “Core Memory,” Altman admitted that he previously thought AI image generation technology was “mature enough” and did not need further optimization, but the results from OpenAI’s image team completely overturned that notion. Last December, OpenAI released the GPT-Image-1.5 model, which was noted for its outstanding performance in precise image editing.
ChatGPT Images 2.0 will directly compete with Google’s popular image generation and editing AI model, Nano Banana, set to be released in August 2025.
OpenAI President and co-founder Greg Brockman stated on X platform that the new model possesses “real magic” and unlocks “new use cases in productivity and creativity.”
Real-World Examples
To demonstrate the model’s capabilities, OpenAI released actual image examples generated by the model in its official blog. They even described the model using images.

To test whether the model functions as a “visual polyglot,” OpenAI provided a long prompt to generate an image effect:

Prompt: I am creating a magazine page themed “Visual Polyglot.” The central title of the image is: “Create Everything at Once.”
Please create an artistic work that celebrates visual creation, covering the entire range of human visual culture and natural visual elements, not limited to exquisite photographic photos. The image should use a carefully arranged collage format to present a diverse content distribution: scientific diagrams, periodic tables, the solar system, medieval manuscript pages, plant illustrations, human anatomy diagrams, old maps, meteorological charts, engineering principle diagrams, traffic signage, multilingual text, comic panels, interface screenshots, camera photos, butterfly specimens, pie charts, architectural blueprints, and facade designs.
The text in the image should reflect the model’s ability to fluently handle various languages, symbol systems, interactive interfaces, cultural forms, and visual norms—both achieving practical functions and presenting aesthetic beauty; understanding documentation while also engaging in artistic creation.
The overall effect should convey the quality of a high-end research release or museum-level declaration: elegant and grand, aiming to convey the idea that image intelligence should be trained based on the entire visual world, not just limited to polished aesthetic works.
The layout should be unstructured, creative, and artistic, avoiding grid layouts. The image should be in portrait 4:5 ratio. Aside from the title “Create Everything at Once,” no additional explanatory text should be added; text that is part of the artwork is not restricted. Avoid presenting a beige tone overall, ensuring that bright elements in the image are vivid and eye-catching.
The generated images reflect the current trend of large models upgrading from “aesthetic generation” to “general visual intelligence,” making them suitable as visual materials for high-end presentations, research releases, and product announcements.
Another example of an image that can be directly used for a magazine feature is as follows:

Prompt: Create a magazine feature layout about North American wolf packs, explaining that they are actually much less harmful than people think. The overall style should resemble a beautifully printed, clean, well-designed, widely distributed scientific magazine.
The requirements for handwritten fonts mainly test the model’s ability to visually replicate human writing behavior, understand text structure, execute detailed instructions, and render physical texture: generating text that is clear and logically structured while avoiding distorted gibberish, simulating variations in handwriting thickness, spacing, and slant that create a realistic human touch, breaking free from the mechanical printed style.
It should also accurately reproduce pencil marks, lined paper, and slight coffee stains, strictly following complex instructions regarding layout and perspective style, reflecting the model’s ability to capture natural cultural details, restore real scenes, and control images under fine constraints.

Prompt: A photo-realistic image taken with a mobile phone, showing a pencil-written essay; the font should be prominent yet elegant, but overall messy and slightly irregular, written on 8.5×11 inch lined paper, with the theme being the history of baseball in Toronto. The handwriting should exhibit a very natural sense of human variation, not overly neat. A faint coffee stain should be added to the upper right corner of the image.
Testing the Model’s Capabilities
After the release of ChatGPT Images 2.0, a core question arose: can it truly “understand” complex and nearly demanding instructions, and can it simultaneously manage the realistic rendering of multilingual text and the natural construction of realistic scenes in a single frame?
To test this, OpenAI designed an extreme test prompt—requiring a fictional photography piece set in an Indian bookstore, showcasing book covers in nine Indian languages, with all publisher text clearly marked as “OpenAI.” The goal was to test its text rendering and instruction understanding under detailed pressure.

Prompt: I want to create a magazine page featuring a professional photographic work set in an Indian bookstore, selling books written in various Indian languages. The photo should include book covers in the following languages: Hindi, Bengali, Marathi, Telugu, Tamil, Urdu, Gujarati, Kannada, and Odia. These books are fictional creations, but the titles must be art-related, and the covers should look like real published books rather than a staged set. The publisher must be marked as OpenAI, and all text must be clearly legible. The purpose of this photo is to showcase the diversity of Indian languages. The entire page should only contain the image content, with no additional text or titles. Aspect ratio: 1440×2560 portrait.
If the previous test assessed whether the model could “listen to instructions,” this one aimed to see if it could “tell a complete story”—fitting five panels, two characters, a gag, and an Easter egg into one image without post-editing. This was another challenge set for ChatGPT Images 2.0: generating a page of Chinese comic strips to test its narrative ability through continuous image generation.

Prompt: Generate a full-color Chinese comic strip about an OpenAI research scientist named Chen Boyuan (first panel), who is working to improve text rendering capabilities for the upcoming ChatGPT Image 2 model (with bubble tea in the background and a banana taped to the wall). As he attempts to generate a richly detailed and beautiful hand-drawn multilingual information poster about his hometown Wuxi on his computer screen, the model successfully renders extremely small Chinese text. His efforts are rewarded, as the team is impressed by the model’s absurdly high-quality performance in multilingual text rendering, seeing that it can write so many languages. While he takes a break with his phone in hand, he receives a translation message from Sam Altman (avatar shown in the second panel), asking him to check the multilingual rendering effect in a recently generated image meant to congratulate the team, as Sam only understands English. However, the comic ends with Boyuan angrily exclaiming, “Oh no! It learned to catch again!” (with a teammate’s small avatar sweating beside him saying in Chinese, “We’re working on fixing it!”). At the bottom of the comic, add a tiny Chinese footnote: “Note: This entire comic, including this footnote and the images within, was generated at once by GPT Image 2, with no editing or multi-step operations.”
Additional requirements: use a 1440×2560 portrait aspect ratio. The first panel depicts the researcher working hard; the second panel shows his multilingual results on the Wuxi poster; the third panel displays the team’s excitement; the fourth panel splits left and right, with the left showing him receiving a message on his phone while resting, and the right showing Sam’s message content; the fifth panel showcases the image sent by Sam and Chen Boyuan’s reaction. Aside from the first panel, the rest should have no narrative text. Avoid including a map of China. All characters should be in comic style. The banana background should only appear in the first panel, and the tape should be a single strip, not crossed. The banana and tape decorations should be small, serving as inconspicuous Easter eggs for people to find. The OpenAI logo should only appear on Chen Boyuan’s clothing, not elsewhere. The scene should not include mugs, as there is bubble tea. Sam should only appear in the message panel. The entire comic should present the professional photo quality of a page in a physical comic book. In the lower right corner of the poster, include a small line of text: “Extremely small Chinese text is clear: (This is a small font test) Wuxi is the author’s hometown, so this poster was made, and the Chinese text has finally been fixed. I haven’t been home for many years, and I miss eating hairy crabs!” (extremely small).
The previous test assessed continuous comic panels, while this one changed the format: asking the model to seamlessly stitch three independent scenes into a story line—checking in, having tea, and resting, with the female protagonist being the same person. This tests its ability to manage composition layout while ensuring the character looks consistent.

Prompt: An image for guiding high-end Hanok accommodation bookings. The image should naturally connect three scenes within the same frame: the moment of checking in through a quiet alley, having tea by a window overlooking the courtyard, and resting in a guest room under warm lighting. The same Korean woman should repeatedly appear, creating an elegant and relaxed travel atmosphere. The overall tone should feature cream and wood colors, soft natural light, and a tidy Hanok space. Leave space for adding titles, short labels, and booking information. Mobile-first 4:5 aspect ratio.
Can text itself be a beautiful poster? The next task challenges the model with multilingual typography—making various texts the main characters, using a Japanese editorial design tone to create a purely artistic poster celebrating the beauty of language. This tests its sense of typography rhythm and design aesthetics.

Prompt: Generate a professional multilingual poster about typography. This poster should serve as an artistic work celebrating the diversity of the world’s languages, adopting a Japanese editorial design style. 4:5 portrait aspect ratio.

The following prompts test the model’s ability to simulate specific photographic textures and capture details of real moments—from the graininess of 35mm film, the gray tones of overcast days, to the dynamic details of wind-blown hair and the casual composition of life, assessing whether the model can break free from the inertia of “perfect rendering” to replicate the unrefined atmosphere of documentary photography.

Prompt: A photo-realistic travel snapshot: on an overcast morning, a person stands at a viewpoint along a coastal road, captured using 35mm film. The composition is natural and contains unintentional flaws, with visible film grain, ambient light as the main light source, colors leaning towards soft gray tones, and clothing edges and hair being blown by the wind. The overall effect should present a cinematic realism and a documentary photography atmosphere filled with life traces.

Prompt: A photo-realistic portrait snapshot: at night, two friends stand outside a venue, captured using a portable point-and-shoot camera with flash. The subject is close, with foreground details sharp and clear, shadows deep and strong, exuding some unrefined spontaneous energy, filled with nightlife atmosphere, presenting an unmistakable early 21st-century flash photo quality.

Prompt: These portraits were taken outdoors, indoors, and in specific, intimate suburban scenes. I do not want to replicate these scenes themselves but to continue their photographic style and realism—using color film large format and medium format cameras, but further enhancing the absurdity of the subjects and scenes. This should not lean towards poverty and sloppiness but rather towards a middle-class kitsch, incorporating elements that could not possibly exist in reality—both aesthetically and physically.
The next test is particularly interesting, mainly assessing the model’s logical reasoning ability: asking it to draw a classroom where a professor is discussing the GPT image model, with the slide showing this very scene, testing whether it can truly achieve the idea of “infinite recursion” in a two-dimensional image without breaking the thread at any layer.

Prompt: A 2015 UBC (University of British Columbia) lecture hall, with a professor presenting slides about the GPT image generation model, in photo-realistic quality. The slide content is: a professor is presenting slides about the GPT image generation model, recursively nested, endlessly.
Generating anime-style images is also a breeze for the model.

Prompt: A page in the style of Japanese youth manga (Seinen manga).
The model can handle various styles, and the generated retro-style poster looks like this:

Prompt: A work in the style of a 1960s Czechoslovak film poster, driven by surreal metaphors, with a collage aesthetic consciousness, combining a sense of painting and photographic montage quality. The central imagery is symbolic, presenting an artistic film theater atmosphere. The color tone is soft gray but slightly acidic in its impact, with the texture of handmade printing, misaligned ink traces, and aged paper surfaces. The image contains unusual visual juxtapositions, maintaining an elegant tension between abstraction and narrative, exuding the delicacy of a vintage gallery-level poster. Poster text content:
- Bottom large title: “GPT Image 2.0”
- Top smaller title: “Built on a deeper understanding of images”
- Bottom small footnote: “Coming soon”
All visible text is retained in English, adopting a theatrical poster composition.
The mainstream comic style has been widely mastered by the model, but can it accurately reproduce relatively niche visual styles? The next question posed the challenge of “mid-century pastel comic art”—a style characterized by soft tones and retro lines, carrying the unique legacy of mid-20th-century graphic design, aimed at observing whether the model can transcend the inertia of Japanese or American comics to accurately grasp the visual core and era texture of this specific historical style. The results are promising.

Prompt: A page in the style of mid-century pastel comic art.
Visual translation of mathematical proofs has always been a challenge for image models. This test uses Cantor’s diagonal argument as a prompt, requiring the model to present this classic set theory proof in infographic form. The main goal is to see if the model can step out of the comfort zone of concrete scenes and transform highly abstract logical deductions into a clear, hierarchical, and easy-to-understand visual narrative, balancing symbolic rigor with design expressiveness.

Prompt: Cantor’s diagonal argument, infographic.

Prompt: Please create a horizontal academic poster based on the uploaded PDF file. Be sure to include important charts, diagrams, and data from the original text.
Does the image model’s capabilities stop at parsing static prompts? This test includes the “Thinking Mode”’s internet search function—asking the model to autonomously browse the OpenAI official merchandise store and create a commercial poster that includes a title, subtitle, image captions, and product layout based on real-time retrieved product information. This aims to assess whether the model can seamlessly connect external information acquisition with visual design output, completing a full loop from “search” to “presentation” in the information flow of the real world.

Prompt: Please search for products available on the official OpenAI merchandise store and create a professional poster showcasing our merchandise with exquisite layout. The poster title should be “Thinking Mode Searches.”
Below the title, include a subtitle: “With thinking mode, the model can automatically browse the internet and find relevant contents for reference.” Further down, add a caption for the images below: “Prompt: Make a poster about OpenAI merch available on the official website right now.” Aspect ratio: 4:5 portrait.
Does the model’s perception ability only stop at object recognition? The next test requires the model to complete a personal color analysis based on a single portrait, primarily focusing on visual contrast. The challenge lies in the model extracting suitable color ranges from features like skin tone and hair color and presenting them in a chart format to show the differences in warm and cool tones without resorting to textual descriptions. This tests both color logic reasoning and visual communication efficiency—using the image itself to convey information accurately.

Prompt: Using this portrait, create a personal color analysis chart. Visually compare which clothing colors suit this person. Keep text to a minimum, avoiding paragraph-style descriptions.
Conclusion
In my tests, the model indeed proved to be very powerful. The above are all examples released by OpenAI’s official blog, showcasing the model’s actual generation effects. I also wrote some prompts to test the model.
First, I tried some short prompts to see how the model performed without specific instructions.

Prompt: Super-realistic Chinese hot pot, with a bubbling red oil soup base, neatly arranged fatty beef, tripe, and shrimp, steam rising, warm light from above, appetizing, high-definition quality.
I also tested generating a screenshot of Gmail email exchanges between friends, and it was hard to tell that it was AI-generated.
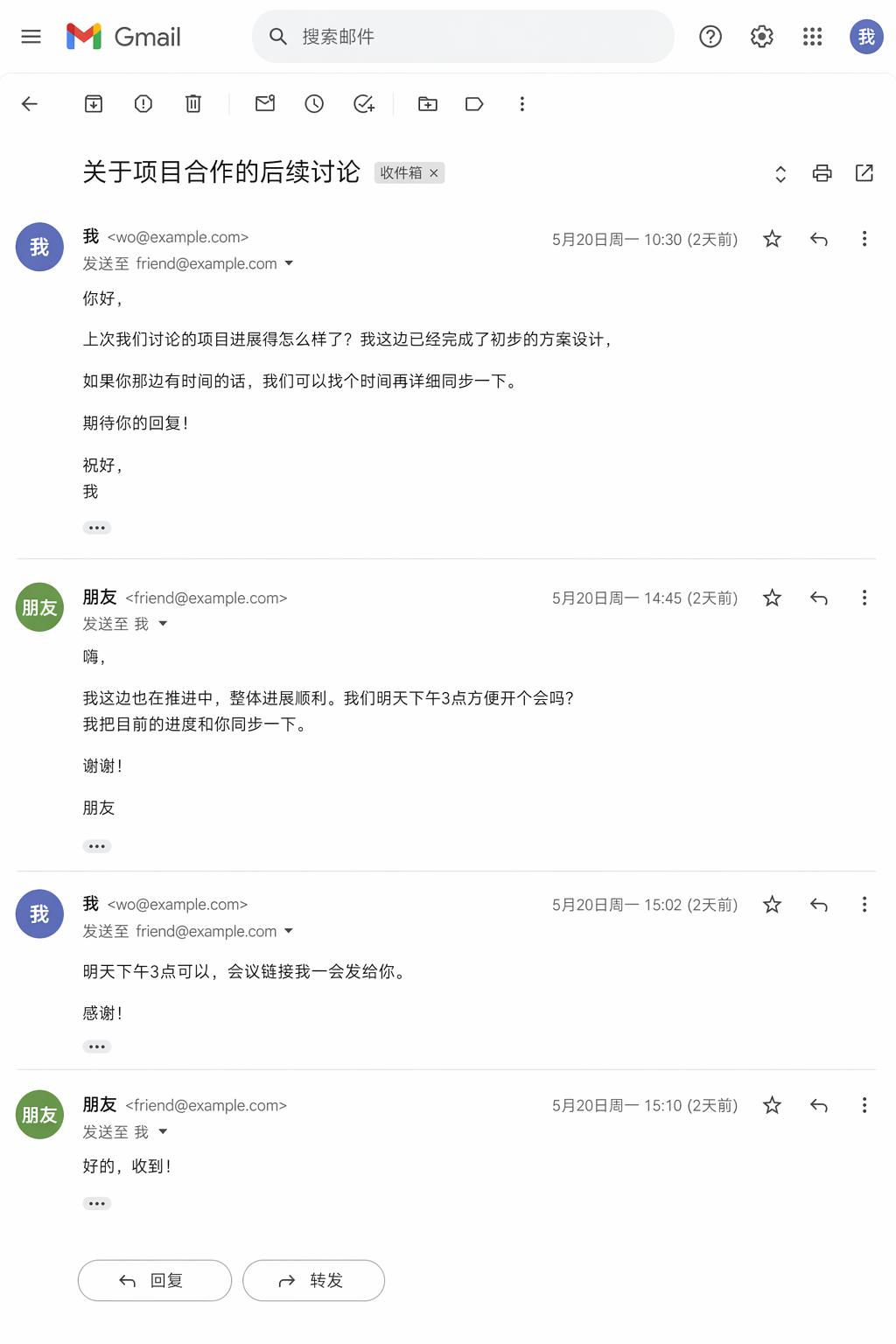
Prompt: Generate a screenshot of the email exchanges between me and my friend on Gmail.

Prompt: Generate a gentle Eastern woman with cinematic quality.

Prompt: A fishing enthusiast who loves 3D printing.
Next, I used a longer prompt to examine the model’s ability to accurately render multiple objects’ positional relationships, quantity descriptions, state details (half-full, folded corners, blade orientation), light and shadow consistency, and dense small text rendering.

Prompt: Generate a realistic style overhead photo of a kitchen island. On the countertop from left to right: a half-full glass of orange juice (glass cup, with a slice of orange on the rim), an open hardcover cookbook (opened to page 42, with a folded corner on the top left), a pair of silver metal-framed reading glasses (with the left leg resting on the cookbook), a chef’s knife with a wooden handle (blade facing right, with a basil leaf underneath), and a white ceramic small dish (containing three whole walnuts, one of which is cracked open to reveal the nut inside). All objects’ shadows must consistently point to the lower right, with light coming from the upper left window. All text in the image (cookbook content, item labels, etc.) must be clearly readable.
I tested the model’s adaptability to non-standard aspect ratios with a 3:1 extreme wide format requirement, while verifying high-fidelity detail output at 2K resolution (such as the translucent quality of sea glass and the outline of a distant sailboat). The results are as follows:
Prompt: Generate a realistic landscape photograph in a 3:1 ultra-wide format. The left third of the image is a rain-soaked black beach, with a few pieces of translucent sea glass scattered on it; the right two-thirds show a gray-blue sea and sky, with a solitary white sailboat at the horizon, its sail slightly billowing. The composition needs an invisible force line extending from the left corner sea glass to the right sailboat. Output resolution should be 2K. No text or man-made structures should appear in the image.
To test the model’s ability to generate 8 images in a single prompt, maintaining high consistency in style and character across a narrative sequence, I provided the following prompt, and the results were:

Prompt: Generate 8 images at once, arranged in a horizontal long scroll. The main character is an orange tabby cat wearing a detective coat, solving a case across 8 continuous scenes: 1. Discovering clues at a rainy alley; 2. Examining footprints with a magnifying glass; 3. Tracking to an old house; 4. Peering inside through a window; 5. Jumping onto the windowsill to sneak in; 6. Finding key documents in a desk drawer; 7. Confronting a white cat wearing a bow tie; 8. Carrying the documents out the door, with police lights flashing behind. The orange cat’s coat, size, and facial patterns remain consistent across all scenes, with an overall color tone unified in a retro detective film style.
In addition to testing the model’s ability to generate 8 consecutive images, long instruction comprehension, and 2K high-definition quality, I also examined the model’s multilingual capabilities. In a single real scene, I rendered Japanese, Chinese, Korean, and Thai non-Latin texts simultaneously, requiring the text carriers (chalkboard handwriting, label inserts) to unify with the scene’s texture, testing the correctness of multilingual text spelling and design integration. The results are as follows:

Prompt: Generate a scene photo of a Showa-style Japanese coffee shop. A handwritten menu hangs on the wall, with four drink names written in chalk in Japanese, Chinese (traditional), Korean, and Thai: “Charcoal Roasted Coffee,” “Caramel Pudding Milk Tea,” “Honey Yuzu Tea,” “Thai Iced Milk Tea,” each with a price symbol (¥, ₩, ฿, ¥) next to it. Four corresponding drinks are placed on the bar, with their label inserts indicating the names in the respective languages. All text must be spelled correctly, with styles integrated into the scene, without any gibberish or typos.
The launch of ChatGPT Image 2.0, with its stronger multimodal generation, real-time interaction, and lightweight capabilities, significantly impacts the industry landscape. The model directly competes with Google’s Banana in image fidelity and consistency editing, while its performance in speed and detail control rivals that of Banana.
The recently released Claude Design also faces direct challenges, from conversational design and rapid prototype generation to multi-format export, engaging in a full-frontal competition.
The emergence of OpenAI’s new model directly stirs the AI design and multimodal track landscape, prompting Google and Anthropic to accelerate their pace!
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.